Fisher-based Optimizers in Deep Learning
This post summarizes the natural-gradient view of deep learning optimization and reviews practical Fisher-based approximations for linear layers in chronological order. The central question is how methods such as KFAC, EKFAC, Shampoo and SOAP make structured preconditioning cheap enough to use in neural networks.
Introduction
Optimization is one of the most important aspects of deep learning. It is non-convex, highly stochastic, and strongly anisotropic, which creates a gap between clean optimization theory and the practice of training large neural networks. Standard first-order methods such as stochastic gradient descent are often insufficient for modern large-scale training [Amari 1993].
The default optimizer in many deep learning pipelines is Adam or AdamW [Kingma and Ba 2014]. Adam is powerful and robust, but it is mostly structure-agnostic: it treats parameters coordinate-wise and ignores the fact that most weights in modern networks live inside linear layers. Fisher-based optimizers try to use this matrix structure to approximate natural-gradient updates without forming the full Fisher matrix.
We consider a discriminative task of the form
\[\mathcal{L}(w) = \mathbb{E}_{(x,y)\sim \mathbb{D}}\, l(f_w(x), y) \to \min_w,\]where $w \in \mathbb{R}^D$ are model parameters and $f_w(x)$ are logits. For a negative log-likelihood loss,
\[l(f_w(x), y) = -\log p(y \mid f_w(x)) =: -\log p_w(y\mid x),\]the optimization problem can be viewed as maximum likelihood estimation.
Natural Gradient
The Fisher Information Matrix [Amari and Nagaoka 2000] for the joint distribution $p_w(y,x)=p_w(y\mid x)p(x)$ is
\[F(w) := \mathbb{E}\left[ \nabla_w \log p_w(y,x)\, \nabla_w \log p_w(y,x)^T \right].\]Since the data distribution $p(x)$ does not depend on $w$, this becomes:
\[F(w) = \mathbb{E}_x\, \mathbb{E}_{y\sim p_w(y\mid x)} \left[ \nabla_w \log p_w(y\mid x)\, \nabla_w \log p_w(y\mid x)^T \right]. \tag{1}\]
The Fisher matrix is positive semidefinite and measures local sensitivity of the predictive distribution to parameter perturbations. It also gives the second-order approximation of KL divergence:
\[\mathrm{KL}(p_w\|p_{w+\Delta w}) \approx \frac{1}{2}\langle F(w)\Delta w,\Delta w\rangle\]for sufficiently small $\Delta w$.
If we treat the model as a statistical manifold with suitable regularity conditions, $F(w)$ defines a Riemannian metric, called the Fisher metric [Amari and Nagaoka 2000]. The steepest descent direction under a Fisher-metric constraint is the natural gradient [Amari 1998]:
\[\Delta w_{\mathrm{nat}} \propto -F(w)^{-1}\nabla \mathcal{L}(w).\]In practice, neural networks are overparameterized, so the Fisher matrix is often singular or nearly singular. Still, the natural-gradient idea is useful: updates are rescaled according to their effect on the predictive distribution. Directions that strongly change the output distribution are damped more, while insensitive directions are damped less.
It is also useful to separate the roles of loss gradient and Fisher matrix. The label information enters through $\nabla \mathcal{L}(w)$, while the Fisher matrix captures how parameters affect the model distribution.
Approximation Setup
Computing and inverting a $D\times D$ Fisher matrix is infeasible for modern models. The expectation over all model outputs can also be expensive. A common replacement is the empirical Fisher:
\[\widehat{F}(w) := \mathbb{E}_{(x,y)\sim \mathbb{D}} \left[ \nabla_w \log p_w(y\mid x)\, \nabla_w \log p_w(y\mid x)^T \right]. \tag{2}\]
The empirical Fisher replaces the model-output expectation with the observed training labels. This makes it much easier to estimate because $\nabla_w \log p_w(y\mid x)$ is already available from ordinary backpropagation.
Typical scalable approximations are:
- Replace the true Fisher with the empirical Fisher.
- Ignore cross-layer interactions and keep block-diagonal Fisher blocks for linear layers.
- Further approximate each linear-layer Fisher block so that inversion or inverse-root multiplication is tractable.
Kronecker Product
For matrices $A\in\mathbb{R}^{n_1\times m_1}$ and $B\in\mathbb{R}^{n_2\times m_2}$, the Kronecker product is
\[A\otimes B := \begin{bmatrix} a_{11}B & \ldots & a_{1m_1}B\\ \ldots & \ldots & \ldots\\ a_{n_1 1}B & \ldots & a_{n_1m_1}B \end{bmatrix} \in \mathbb{R}^{n_1n_2\times m_1m_2}.\]The main identities used below are:
\[(A\otimes B)(A'\otimes B')=(AA')\otimes(BB'),\] \[(A\otimes B)^T=A^T\otimes B^T,\] \[(A\otimes B)\operatorname{vec}(V)=\operatorname{vec}(BVA^T),\]and
\[\operatorname{vec}(ab^T)=b\otimes a.\]If $A,B\succ 0$, then $(A\otimes B)^\alpha=A^\alpha\otimes B^\alpha$ for any real $\alpha$.
Empirical Fisher for Linear Layers
Consider a weight matrix $W\in\mathbb{R}^{D_{\mathrm{out}}\times D_{\mathrm{in}}}$ with output $y=Wx$. Let $\delta:=\nabla_y l$ be the sample-wise gradient with respect to the layer output. For one sample,
\[\mathcal{G}=\delta x^T, \qquad \operatorname{vec}(\mathcal{G})=x\otimes\delta.\]The full gradient is
\[G:=\mathbb{E}[\mathcal{G}].\]The empirical Fisher block for $W$ is:
\[F = \mathbb{E}\left[ \operatorname{vec}(\mathcal{G}) \operatorname{vec}(\mathcal{G})^T \right] = \mathbb{E}\left[ xx^T\otimes\delta\delta^T \right]. \tag{3}\]
This form makes matrix-vector products feasible, but direct inversion is still too expensive.
For convolutional layers, the same idea applies after patch extraction. If
\[X\in\mathbb{R}^{B\times C_{\mathrm{in}}\times H_{\mathrm{in}}\times W_{\mathrm{in}}},\]then local patches can be unfolded into
\[\mathrm{patches}(X) \in \mathbb{R}^{(B H' W')\times (C_{\mathrm{in}}k_hk_w)}.\]The convolution kernel becomes a matrix
\[W\in\mathbb{R}^{C_{\mathrm{out}}\times (C_{\mathrm{in}}k_hk_w)},\]so the same Fisher approximations can be applied.
KFAC
Inverting the empirical Fisher from Eq. 3 directly is infeasible. KFAC addresses this with a Kronecker factorization [Martens and Grosse 2015]:
\[F = \mathbb{E}\left[xx^T\otimes\delta\delta^T\right].\]KFAC assumes approximate independence between inputs $x$ and output gradients $\delta$:
\[F \approx \mathbb{E}[xx^T]\otimes\mathbb{E}[\delta\delta^T] = F_x\otimes F_y. \tag{4}\]
The inverse action is tractable:
\[(F_x\otimes F_y)^{-1}\operatorname{vec}(V) = \operatorname{vec}(F_y^{-1}VF_x^{-1}).\]Thus the preconditioned matrix gradient has the form
\[\widetilde{G} \propto F_y^{-1}GF_x^{-1}.\]Intuitively, $F_y$ decorrelates rows while $F_x$ decorrelates columns. KFAC was one of the first scalable natural-gradient approximations for neural networks.
KFAC for a linear layer
- Estimate $G_t\gets \nabla_W\mathcal{L}$.
- Update $L_t\gets\beta_2L_{t-1}+(1-\beta_2)\mathbb{E}[\delta\delta^T]$.
- Update $R_t\gets\beta_2R_{t-1}+(1-\beta_2)\mathbb{E}[xx^T]$.
- Every $T_{\mathrm{inv}}$ steps, compute $L_t=Q_L\Sigma_LQ_L^T$ and $R_t=Q_R\Sigma_RQ_R^T$.
- Precondition
- Update momentum and weights:
EKFAC
Eigenvalue-corrected KFAC, or EKFAC, improves KFAC by estimating eigenvalues more accurately [George et al. 2018]. Let
\[F_x=Q_x\Sigma_xQ_x^T, \qquad F_y=Q_y\Sigma_yQ_y^T.\]KFAC implies
\[\widehat{F} = F_x\otimes F_y = (Q_x\otimes Q_y)(\Sigma_x\otimes\Sigma_y)(Q_x\otimes Q_y)^T.\]EKFAC keeps the Kronecker eigenbasis but corrects the eigenvalues:
\[F \approx (Q_x\otimes Q_y)\Sigma^*(Q_x\otimes Q_y)^T, \tag{5}\]
where $\Sigma^*$ is diagonal. Since
\[F = \mathbb{E}\left[ \operatorname{vec}(\mathcal{G}) \operatorname{vec}(\mathcal{G})^T \right],\]the corrected diagonal can be computed as
\[\Sigma^* = \mathbb{E} \left[ \left( (Q_x\otimes Q_y)^T\operatorname{vec}(\mathcal{G}) \right)^{\odot 2} \right] = \operatorname{vec} \left( \mathbb{E} \left[ (Q_y^T\mathcal{G}Q_x)^{\odot 2} \right] \right).\]This avoids forming the full Fisher matrix. EKFAC is also guaranteed to be no worse than KFAC in Frobenius-norm approximation error [George et al. 2018]:
\[\|F-\widehat{F}_{\mathrm{EKFAC}}\|_F \le \|F-\widehat{F}_{\mathrm{KFAC}}\|_F.\]Shampoo
Shampoo was introduced from online convex optimization rather than natural gradient [Gupta et al. 2018], but it has a useful heuristic connection to Fisher preconditioning.
Starting from Eq. 3, consider a rough square of the Fisher:
\[F^2 = \left(\mathbb{E}[xx^T\otimes\delta\delta^T]\right) \left(\widehat{\mathbb{E}}[\hat{x}\hat{x}^T\otimes\hat{\delta}\hat{\delta}^T]\right).\]After expanding and swapping the scalar terms $x^T\hat{x}$ and $\delta^T\hat{\delta}$ between Kronecker factors, one obtains the heuristic approximation
\[F^2 \approx \mathbb{E}\widehat{\mathbb{E}}[\mathcal{G}^T\widehat{\mathcal{G}}] \otimes \mathbb{E}\widehat{\mathbb{E}}[\mathcal{G}\widehat{\mathcal{G}}^T] = G^TG\otimes GG^T.\]This suggests:
\[F \approx \left(G^TG\otimes GG^T\right)^{1/2}. \tag{6}\]
So Shampoo’s left and right preconditioners, $GG^T$ and $G^TG$, can be interpreted as a structured Fisher-style approximation.
Original Shampoo update
- Estimate $G_t\gets\nabla_W\mathcal{L}$.
- Accumulate $L_t\gets L_{t-1}+G_tG_t^T$.
- Accumulate $R_t\gets R_{t-1}+G_t^TG_t$.
- Update
The original Shampoo paper proves an $O(\sqrt{T})$ regret bound in online convex optimization, which corresponds to an $O(1/\sqrt{T})$ stochastic optimization rate [Gupta et al. 2018]. In practice, EMA averaging with coefficient $\beta_2$ is often preferred.
SOAP
Shampoo has a similar eigenvalue issue as KFAC: the eigenbasis may be useful, but the implied eigenvalues can be poor. SOAP applies an EKFAC-like eigenvalue correction to Shampoo [Vyas et al. 2024].
Conceptual relation
\[\begin{array}{ccc} \text{KFAC} & \longrightarrow & \text{EKFAC}\\ \text{Shampoo} & \longrightarrow & \text{SOAP} \end{array}\]EKFAC can be viewed as an eigenbasis refinement of KFAC, while SOAP plays a similar role relative to Shampoo.
The ideal corrected eigenvalues would be
\[\Sigma^* = \mathbb{E}\left[ (Q_y^T\mathcal{G}Q_x)^{\odot 2} \right],\]but this requires per-sample gradients. SOAP instead uses the full gradient:
\[\Sigma^* \approx (Q_y^TGQ_x)^{\odot 2},\]and accumulates this quantity as a second moment via EMA.
SOAP then performs an Adam-like update in Shampoo’s eigenbasis:
- Accumulate momentum $M$.
- Rotate both momentum $M$ and gradient $G$ to the Shampoo eigenbasis.
- Accumulate the second moment $\Sigma^*$ in that eigenbasis.
- Apply Adam-style normalization in the eigenbasis.
- Rotate the update back to the original parameter space.
SOAP also avoids expensive repeated eigendecomposition. It uses randomized SVD-style iterations
\[Q_t\gets \mathrm{QR}(AQ_{t-1}),\]which converge to the eigenvectors of $A$ under standard assumptions. If eigenvectors change slowly, one QR iteration every $k$ steps is often enough.
SOAP for a linear layer
- Estimate $G_t\gets\nabla_W\mathcal{L}$.
- Update momentum $M_t\gets\beta_1M_{t-1}+(1-\beta_1)G_t$.
- Accumulate $L_t\gets\beta_2L_{t-1}+(1-\beta_2)G_tG_t^T$.
- Accumulate $R_t\gets\beta_2R_{t-1}+(1-\beta_2)G_t^TG_t$.
- Every $k$ steps, improve eigenvectors:
- Rotate:
- Accumulate eigenbasis second moment:
- Apply Adam in the eigenbasis and rotate back:
- Update $W_t\gets W_{t-1}-\eta U_t$.
Muon
Bernstein observed that if Shampoo does not accumulate preconditioning matrices, equivalently $\beta_2=0$, then the update becomes [Bernstein 2024]:
\[(GG^T)^{-1/4}G(G^TG)^{-1/4}.\]If $G=U\Sigma V^T$ is an SVD, the update reduces to
\[UV^T,\]which is the matrix sign or polar factor [Higham 2008]. This object can be interpreted as:
- Orthogonalization:
- Steepest descent under a spectral-norm constraint:
Muon, short for Momentum Orthogonalized with Newton-Schulz, builds on this idea [Jordan et al. 2024]. Subsequent work studied how to scale Muon to large language model training [Liu et al. 2025].
Muon for a linear layer (Moonlight lr scaling)
- Estimate $G_t\gets\nabla_W\mathcal{L}(W_t)\in\mathbb{R}^{m\times n}$.
- Accumulate momentum $M_t\gets\beta M_{t-1}+G_t$.
- Use Nesterov momentum $\widehat{M}_t\gets\beta M_t+G_t$.
- Orthogonalize:
- Update
Here $\mathrm{NS5}$ denotes five Newton-Schulz iterations for approximate orthogonalization. This line of work is still developing, with variants such as Polar Express [Amsel et al. 2025] and Gram Newton-Schulz [Zhang et al. 2026]. Muon is currently a practical optimizer for LLM linear layers and is increasingly used as an AdamW alternative.
Experiments
Fisher Matrix Visualization
The first experiment visualizes Fisher matrices for a small MNIST CNN with roughly 3800 parameters. Fisher approximations were computed after the 10th epoch, when the model was already well fitted.
Figure 2 shows six matrices using logarithms of absolute values. The first row contains the true Fisher (Eq. 1), KFAC (Eq. 4), and Shampoo (Eq. 6). The second row contains the empirical Fisher (Eq. 2), EKFAC (Eq. 5), and SOAP.
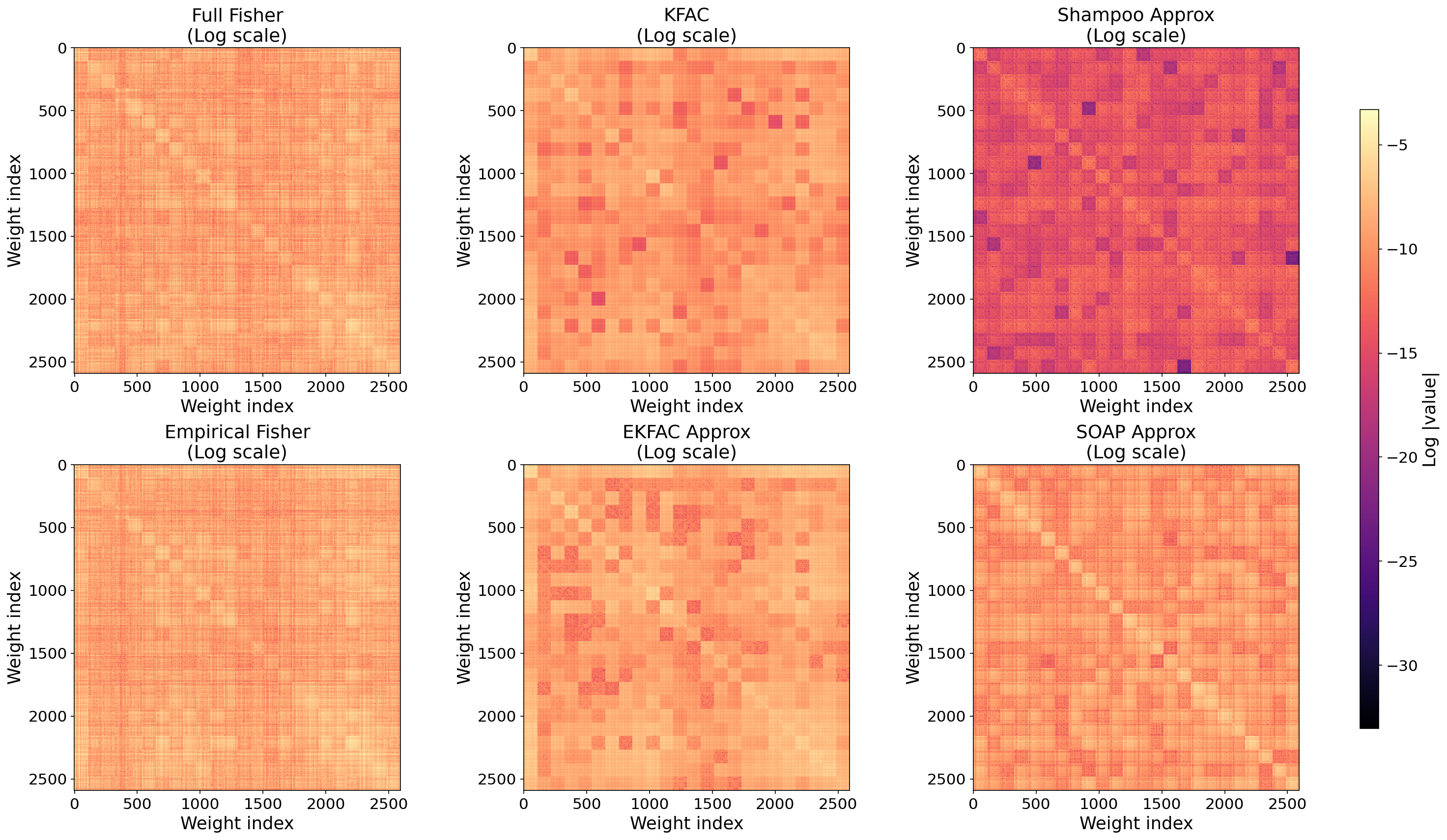
The empirical Fisher is visually close to the true Fisher. This is plausible because the model is already well fitted and the model distribution is close to the data distribution. The small number of classes also helps. For LLM-like tasks with large vocabularies, the true Fisher can differ much more from the empirical Fisher.
KFAC and Shampoo show visible block structure. Shampoo has lower intensity, which may indicate poor eigenvalue approximation. SOAP and EKFAC improve these eigenvalues and smooth the block structure.
LLM Experiment
The second experiment pretrains a small GPT-like model with roughly 10M parameters on Shakespeare-char. AdamW from Andrej Karpathy’s baseline was compared with Fisher-based optimizers. All optimizers that use SVD, meaning all except Muon and AdamW, use preconditioning every 10 steps.
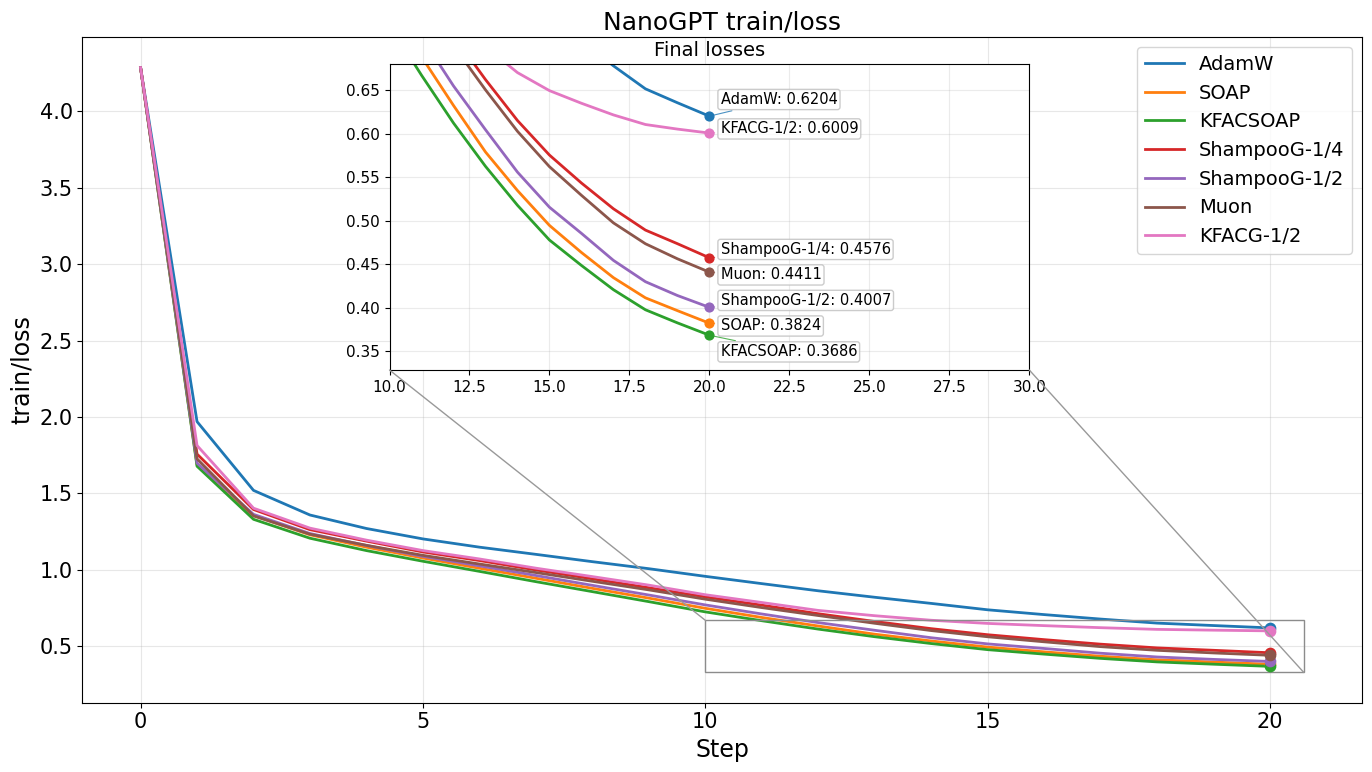
KFAC was run with power $-1/2$ instead of $-1$ because the latter was unstable and performed poorly. A suffix “G” indicates grafting, where the update is rescaled to have the Frobenius norm of the Adam update. This stabilizes the step size.
Shampoo was tested with powers $-1/4$, as in the original version, and $-1/2$, which corresponds more closely to inverting the Fisher instead of using its inverse square root. In this experiment, $-1/2$ performed significantly better. Muon performed similarly to Shampoo with power $-1/4$, but was substantially faster.
SOAP performed best among the considered optimizers. KFACSOAP is a SOAP modification where eigenvectors are computed using the KFAC approximation from Eq. 4 rather than the Shampoo approximation. It outperformed original SOAP in this experiment, suggesting that the KFAC approximation can be more accurate than Shampoo’s approximation in this setting.
Overall, SOAP-style optimizers performed best, supporting the idea that running Adam in an approximate Fisher eigenbasis is a strong practical recipe.
Conclusion
Fisher-based optimizers can be viewed as attempts to approximate natural-gradient preconditioning in ways that fit modern neural networks. KFAC and EKFAC use activation and output-gradient statistics. Shampoo and SOAP use gradient-matrix structure. Muon can be understood as an efficient orthogonalized update arising from a limiting Shampoo-like view.
The experiments here suggest that SOAP-based methods are the most sample-efficient among the tested optimizers. A promising direction is improving eigenvector approximations. In the Shakespeare-char experiment, a KFAC-style eigenbasis worked better than Shampoo’s eigenbasis, which suggests that the choice of structured Fisher approximation still matters.
References
Amari, S. (1993). Backpropagation and stochastic gradient descent method. Neurocomputing, 5(4-5), 185-196.
Kingma, D. P., and Ba, J. (2014). Adam: A Method for Stochastic Optimization. arXiv:1412.6980.
Amari, S., and Nagaoka, H. (2000). Methods of Information Geometry. American Mathematical Society.
Amari, S. (1998). Natural gradient works efficiently in learning. Neural Computation, 10(2), 251-276.
Martens, J., and Grosse, R. (2015). Optimizing Neural Networks with Kronecker-factored Approximate Curvature. ICML.
George, T., Laurent, C., Bouthillier, X., Ballas, N., and Vincent, P. (2018). Fast Approximate Natural Gradient Descent in a Kronecker-factored Eigenbasis. NeurIPS.
Gupta, V., Koren, T., and Singer, Y. (2018). Shampoo: Preconditioned Stochastic Tensor Optimization. ICML.
Vyas, N., Morwani, D., Zhao, R., Kwun, M., Shapira, I., Brandfonbrener, D., Janson, L., and Kakade, S. (2024). SOAP: Improving and Stabilizing Shampoo using Adam. arXiv:2409.11321.
Bernstein, J., and Newhouse, L. (2024). Old Optimizer, New Norm: An Anthology. arXiv:2409.20325.
Higham, N. J. (2008). Functions of Matrices: Theory and Computation. SIAM.
Jordan, K., Jin, Y., Boza, V., You, J., Cesista, F., Newhouse, L., and Bernstein, J. (2024). Muon: An optimizer for hidden layers in neural networks. Blog post.
Liu, J., Su, J., Yao, X., Jiang, Z., Lai, G., Du, Y., Qin, Y., Xu, W., Lu, E., Yan, J., Chen, Y., Zheng, H., Liu, Y., Liu, S., Yin, B., He, W., Zhu, H., Wang, Y., Wang, J., Dong, M., Zhang, Z., Kang, Y., Zhang, H., Xu, X., Zhang, Y., Wu, Y., Zhou, X., and Yang, Z. (2025). Muon is Scalable for LLM Training. arXiv:2502.16982.
Amsel, N., Persson, D., Musco, C., and Gower, R. M. (2025). The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm. arXiv:2505.16932.
Zhang, J., Amsel, N., Chen, B., and Dao, T. (2026). Gram Newton-Schulz: A Fast, Hardware-Aware Newton-Schulz Algorithm for Muon. Blog post and implementation note.